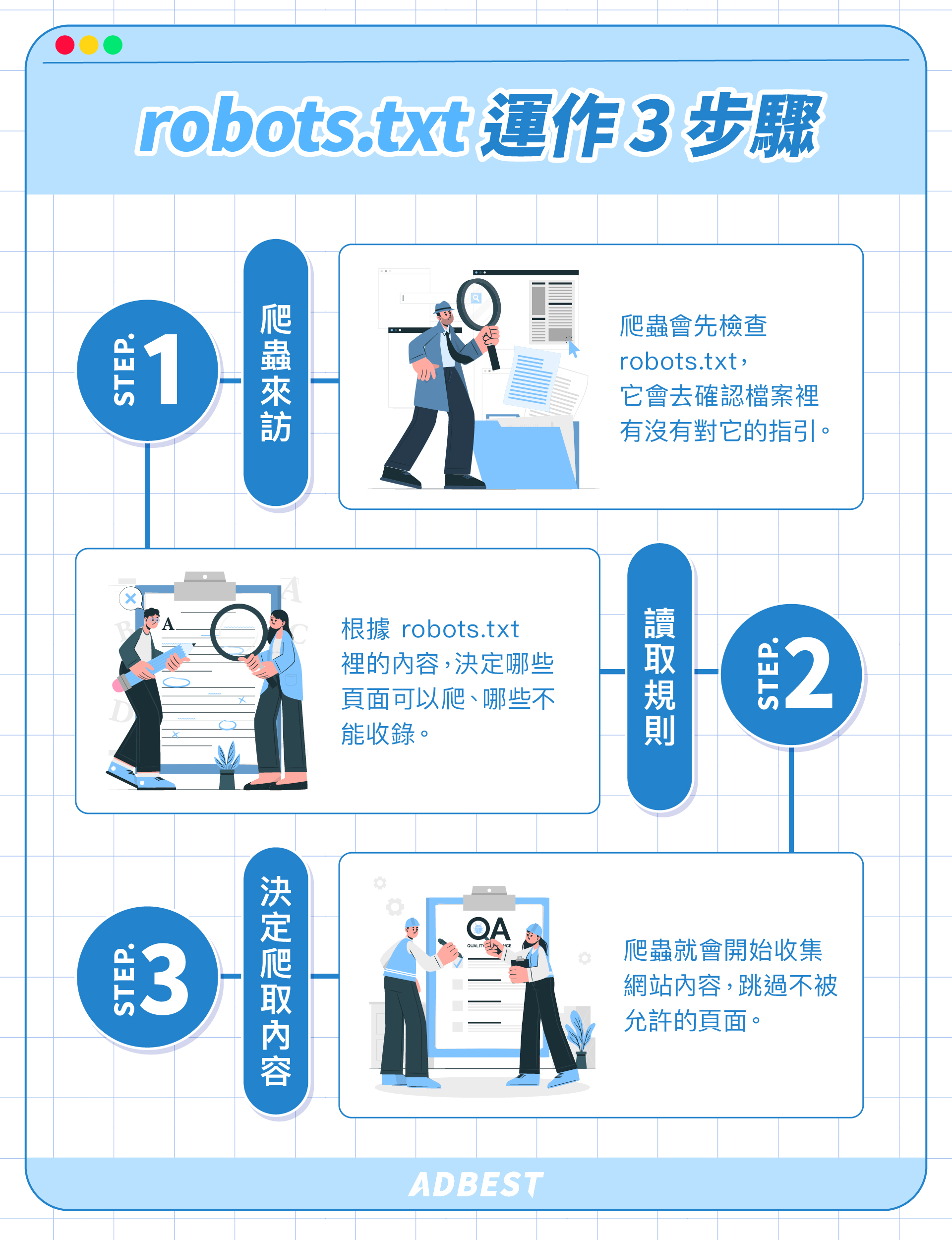
避免robots.txt錯誤與內容稀少等常見收錄障礙,主要應注意以下幾點:
-
確保robots.txt語法正確
robots.txt檔案必須符合標準語法,避免拼寫錯誤或格式錯誤,例如Allow和Disallow指令的正確使用。可利用Google Search Console的robots.txt測試工具檢查語法錯誤,及時修正。 -
合理使用Disallow與Allow指令
不要過度使用Disallow指令阻擋大量內容,避免阻擋重要頁面被搜尋引擎爬取。對於需要開放的頁面,應明確使用Allow指令允許爬取。 -
robots.txt檔案大小與格式限制
檔案必須是UTF-8編碼的純文字檔,大小不超過500 KiB,過大會導致搜尋引擎忽略部分規則。檔案中每行需以CR、CR/LF或LF分隔。 -
避免伺服器錯誤影響robots.txt讀取
確保robots.txt檔案不會回傳HTTP 5XX錯誤,否則搜尋引擎可能停止爬取整個網站。 -
定期檢查與更新robots.txt
網站結構或內容變動後,應更新robots.txt,並利用Google Search Console的網址審查工具確認變更生效,提交網站地圖加速收錄。 -
避免內容稀少頁面被收錄
對於內容稀少或測試頁面,可透過robots.txt阻擋爬取,或使用meta robots標籤設定noindex,避免這些頁面影響整體SEO品質。 -
針對不同網站類型調整robots.txt策略
例如電商網站可阻擋購物車、結帳頁面;會員網站阻擋會員專區;新聞網站可設定Crawl-delay減少伺服器負擔。
綜合以上,避免robots.txt錯誤與內容稀少障礙的關鍵是正確撰寫與定期維護robots.txt檔案,合理控制爬取範圍,並配合meta標籤管理內容收錄,同時利用Google Search Console等工具持續監控與調整。