robots.txtとnoindexタグの設定ミスを防ぐポイントは以下の通りです。
-
robots.txtの設定ミスを防ぐポイント
- サイトのURL構造を正確に把握し反映する
実際のURL構造と異なるパスを指定すると、重要なページがクロールされなかったり、不要なページがクロールされる恐れがあるため、正確なパス指定が必須です。 - User-agentの指定に注意する
すべてのクローラーに適用したい場合はUser-agent: *を使うが、特定のクローラーだけに適用したい場合は誤指定に注意する。 - 構文エラーを避ける
robots.txtの記述ミス(ファイルパスの間違い、誤ったディレクティブなど)を防ぐため、専用のテストツールやGoogle Search Consoleのrobots.txtテスターを活用し、設定後に必ず動作確認を行う。 - ディレクトリ単位でのブロックは慎重に
ディレクトリ全体をブロックすると意図しないページまでクロール拒否になることがあるため、必要に応じて個別ページ単位で設定することが望ましい。 - 複数人でのダブルチェックを実施する
設定ミスの再発防止策として、実装者以外の複数名で内容を確認することが推奨される。
- サイトのURL構造を正確に把握し反映する
-
noindexタグの設定ミスを防ぐポイント
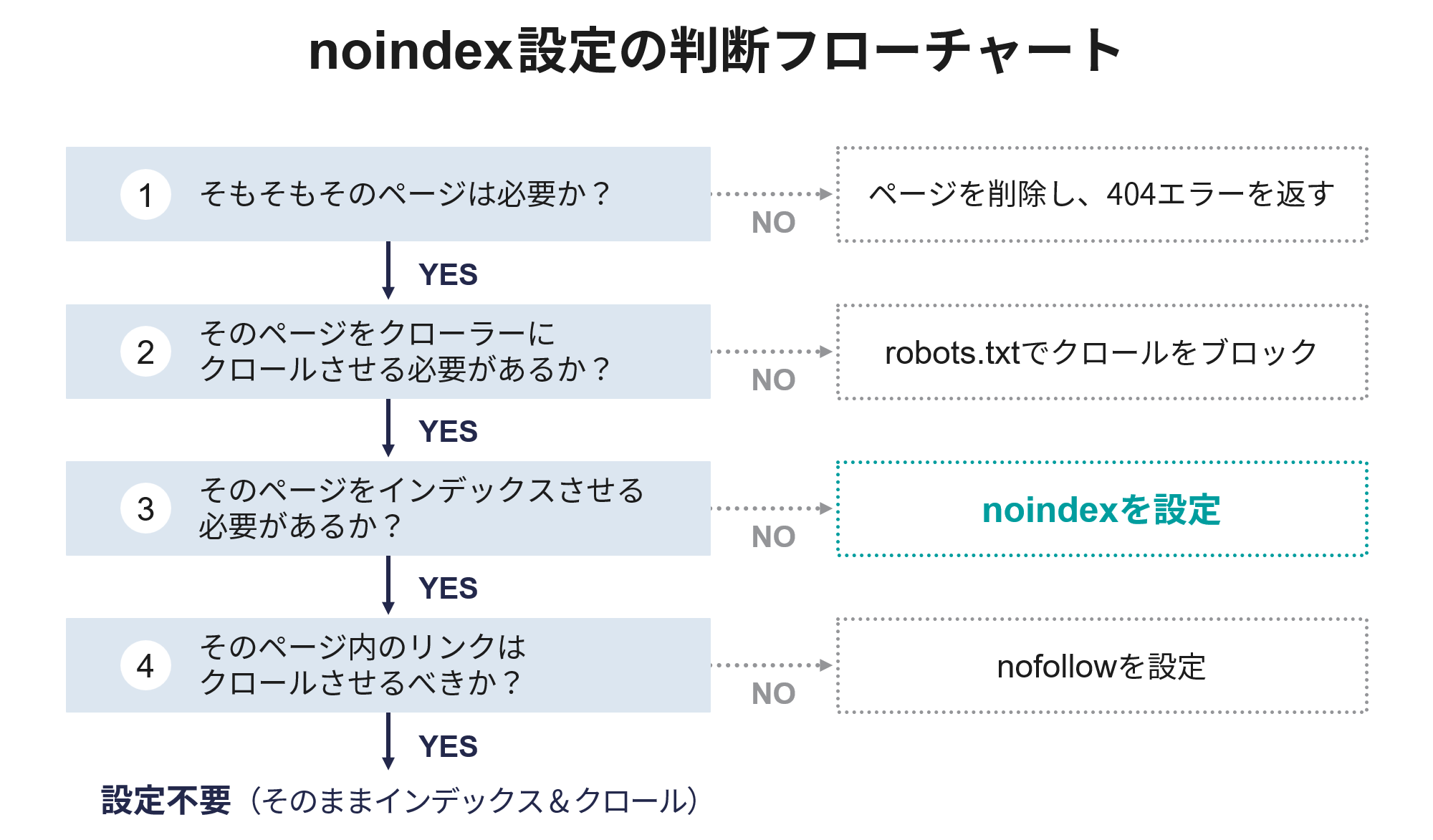
- noindexはクロール拒否ではなくインデックス拒否であることを理解する
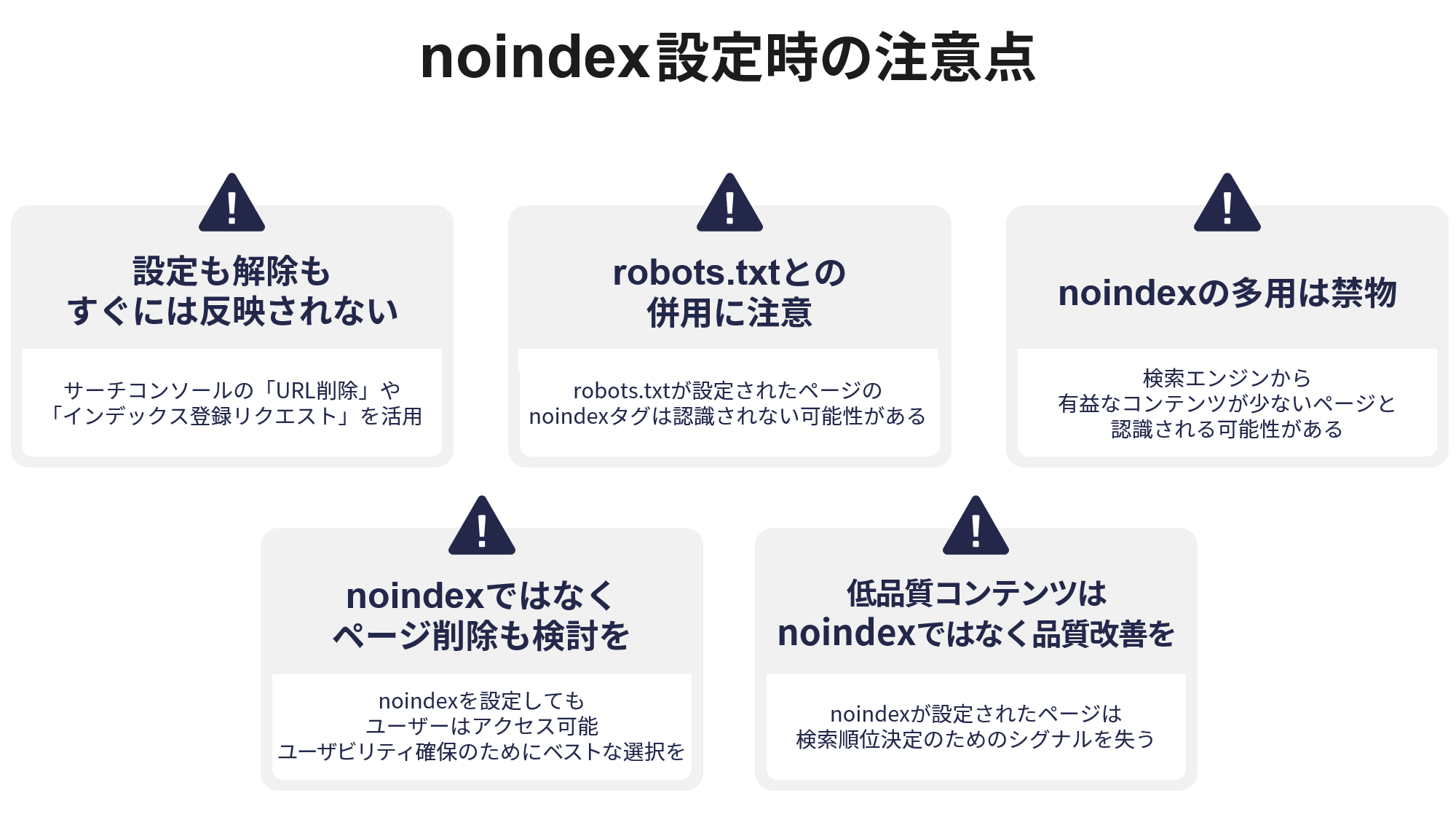
noindexタグはページのインデックス登録を拒否するが、クロール自体は許可するため、robots.txtでクロール拒否するとnoindexが機能しなくなる場合がある。 - 不要なnoindexタグを設定しない
テストページやテンプレートに誤ってnoindexを設定したまま公開すると、流入が減少しSEOに悪影響を及ぼすため、設定漏れや重複をチェックする。 - noindexを設定しすぎない
多用するとサイト全体の流入が減り、評価低下のリスクがあるため、必要なページだけに限定して設定する。 - 正しい場所に正しく記述する
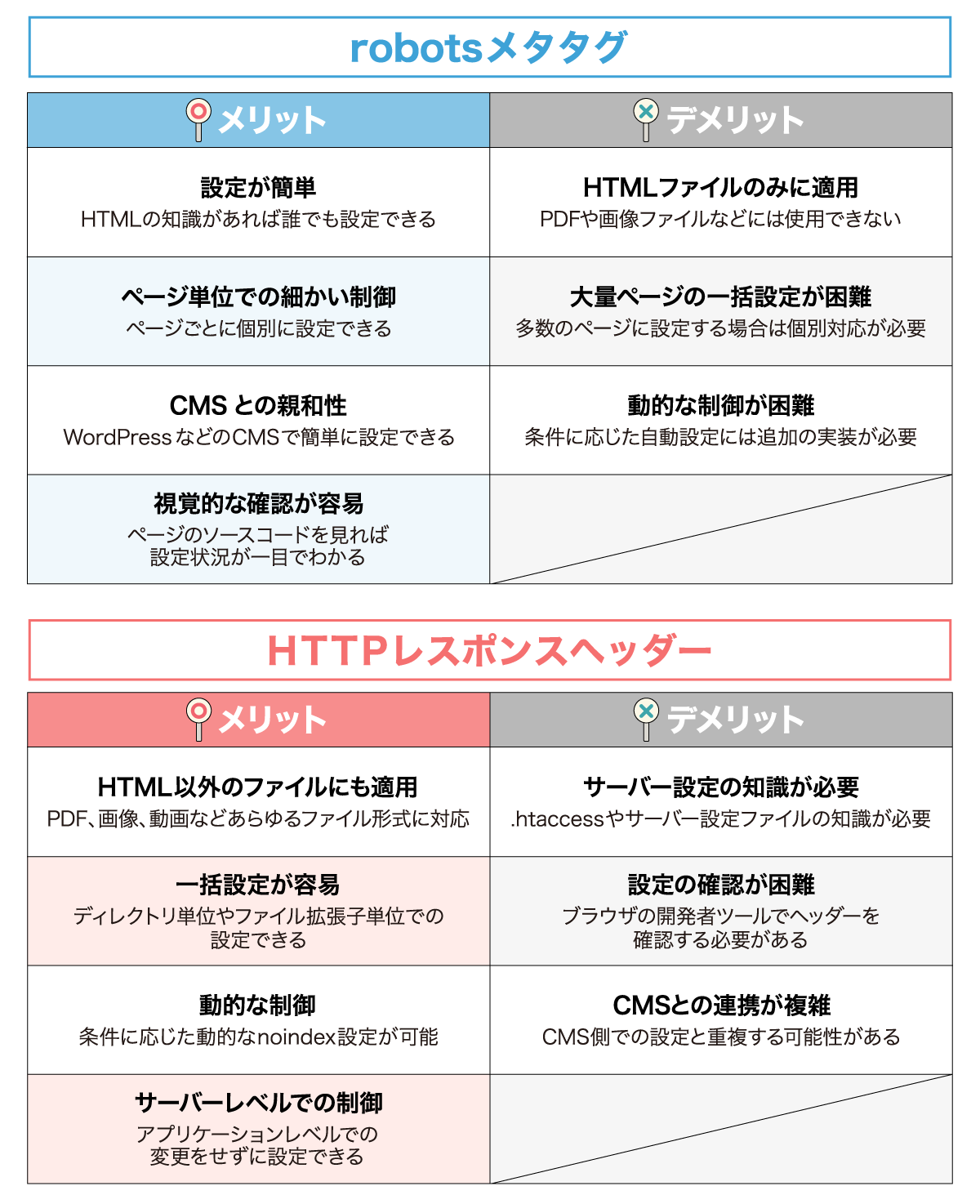
HTMLの<head>内に<meta name="robots" content="noindex">を記述するか、HTTPレスポンスヘッダーで設定する。CMSの管理画面から設定できる場合もある。
- noindexはクロール拒否ではなくインデックス拒否であることを理解する
-
robots.txtとnoindexの併用時の注意
- robots.txtでクロール拒否したページにnoindexを設定しても効果がない
クロールされなければnoindexタグが検索エンジンに認識されないため、両者の役割を理解し使い分けることが重要。 - noindexとnofollowを併用することでインデックス拒否とリンク評価の伝達拒否が可能。
- robots.txtは必ずルートディレクトリに設置し、サイトマップも活用してインデックスさせたいページを明確に伝える。
- robots.txtでクロール拒否したページにnoindexを設定しても効果がない
-
設定後の確認と運用
- Google Search Consoleなどのツールでクロール状況やインデックス状況を定期的に確認する。
- 設定変更時はテスト環境で動作確認を行い、本番反映前に問題がないか検証する。
- 設定内容のドキュメント化と複数人でのレビュー体制を整える。
これらのポイントを守ることで、robots.txtとnoindexタグの設定ミスを防ぎ、SEO上の不具合を回避できます。