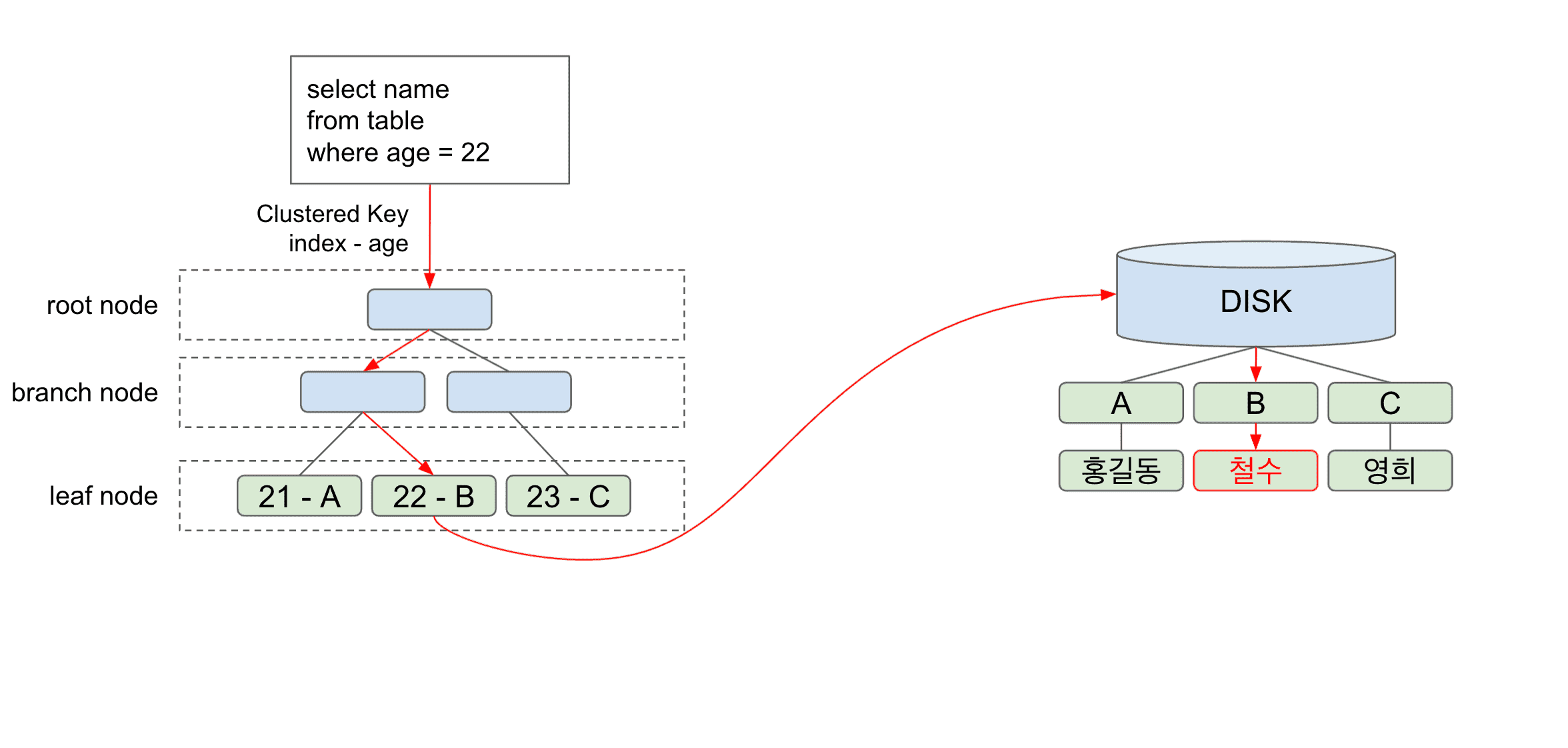
인덱싱 과정에서 흔히 하는 실수와 회피 방법은 다음과 같습니다.
흔한 실수
- 불필요한 인덱스 남발: 모든 컬럼에 인덱스를 생성하면 오히려 성능 저하와 자원 낭비가 발생한다. 특히 자주 변경되는 컬럼에 인덱스를 만들면 쓰기 작업 성능이 떨어진다.
- 잘못된 인덱스 설계: 다중 열(복합) 인덱스에서 열 순서를 잘못 정하거나, 여러 열을 개별 인덱스로 생성하는 경우가 많다. 이는 인덱스 효율을 크게 떨어뜨린다.
- 중복도가 높은 컬럼에 인덱스 생성: 예를 들어 성별처럼 값이 제한적인 컬럼에 인덱스를 만들면 인덱스 효과가 거의 없다.
- 인덱스 유지보수 소홀: 인덱스가 파편화되거나 오래된 인덱스가 방치되면 검색 효율이 감소한다.
- 검색 쿼리와 인덱스 미일치: 인덱스가 지원하지 않는 쿼리 유형을 사용하면 인덱스의 장점이 사라진다.
- 과도한 복잡한 인덱스 구조 사용: 지나치게 복잡한 인덱스는 관리가 어렵고 오히려 성능 저하를 초래할 수 있다.
- 대용량 데이터에 부적절한 클러스터형 인덱스 사용: 자주 입력되는 대용량 데이터에 클러스터형 인덱스를 쓰면 부하가 커진다.
회피 방법
- 필요한 컬럼에만 인덱스 생성: 자주 검색에 사용되는 컬럼 위주로 인덱스를 설계하고, 변경이 잦은 컬럼에는 신중하게 적용한다.
- 복합 인덱스 설계 시 열 순서 신중히 결정: WHERE 절 조건에 자주 등장하는 열 순서대로 인덱스를 구성한다. 여러 개의 개별 인덱스 대신 복합 인덱스를 활용한다.
- 중복도와 분포도 고려: 중복도가 높은 컬럼은 인덱스 생성 대상에서 제외하거나, 유니크 인덱스가 효과적인 경우에만 사용한다.
- 인덱스 상태 주기적 점검 및 재구성: 인덱스 파편화를 방지하기 위해 주기적으로 인덱스를 재구성하거나 최적화한다.
- 쿼리와 인덱스 매칭 확인: EXPLAIN 등 도구를 사용해 쿼리가 인덱스를 제대로 활용하는지 점검한다.
- 과도한 인덱스 생성 자제: 인덱스가 많으면 관리 비용과 쿼리 계획 비용이 증가하므로 꼭 필요한 인덱스만 유지한다.
- 대용량 데이터에는 적절한 인덱스 유형 선택: 클러스터형 인덱스 대신 유니크 인덱스 등 부하를 줄일 수 있는 방식을 고려한다.
이처럼 인덱싱 과정에서의 실수를 피하려면, 데이터 특성과 쿼리 패턴을 충분히 분석하고, 인덱스 설계 원칙을 준수하며, 주기적인 모니터링과 유지보수가 필수적입니다.
.webp)