识别和监测网站中的404页面,主要可以通过以下几种方法:
-
HTTP状态码检查
发送HTTP请求并检查服务器返回的状态码,404页面通常会返回状态码404(Not Found)。这是最直接和标准的检测方式,可以用编程语言(如Python的requests库)或爬虫工具实现。 -
页面内容分析
有些网站自定义了404页面,返回的状态码可能不是404,而是200等正常状态码。此时可以通过抓取页面内容,搜索包含“404”、“页面未找到”、“Not Found”等关键词,或者与已知404页面内容做相似度比对来判断是否为404页面。 -
相似度比对法
先请求一个网站上绝对不存在的路径,获取该网站自定义404页面的HTML代码,再与目标页面HTML做相似度计算(如使用difflib库),相似度高于某个阈值(如90%)则判定为404页面。 -
使用网站爬虫工具
如Screaming Frog等爬虫工具可以自动爬取网站,检测所有链接的状态码,自动识别404页面,方便批量监测。 -
日志分析
通过分析网站访问日志,识别用户访问时返回404状态码的请求,了解404页面的访问情况和来源,辅助定位问题。 -
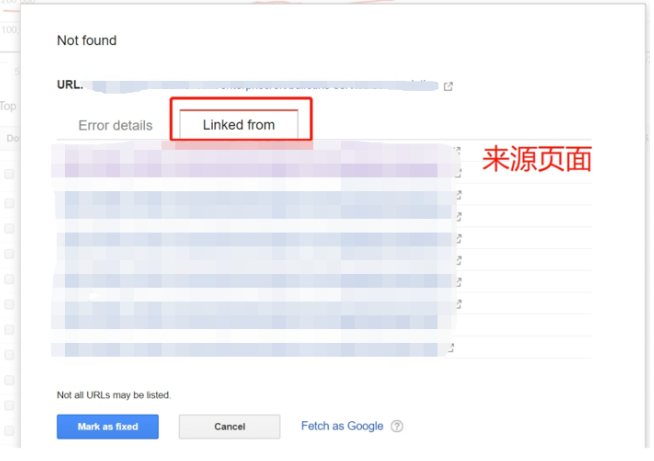
Google Search Console等SEO工具
Google Search Console可以报告网站中的404错误页面,提供错误发生频次和来源链接,帮助站长及时发现和处理404错误。 -
自动化测试和截图比对
使用自动化测试工具(如Selenium)模拟浏览器访问,截取页面截图,与标准404页面截图进行比对,判断是否为404页面。 -
定期内容审计和CMS自动检测
结合内容管理系统自动检测失效链接,配合人工检查,减少死链和404页面的产生。
综上,识别和监测404页面的关键是结合HTTP状态码检测和页面内容分析,辅以爬虫工具和日志分析,形成持续监控机制,及时发现并处理404错误,提升用户体验和SEO表现。