Google索引机制主要包括三个阶段:抓取(Crawling)、索引编制(Indexing)和搜索结果呈现(Serving)。其中,Googlebot是负责抓取网页的自动程序。
具体过程如下:
-
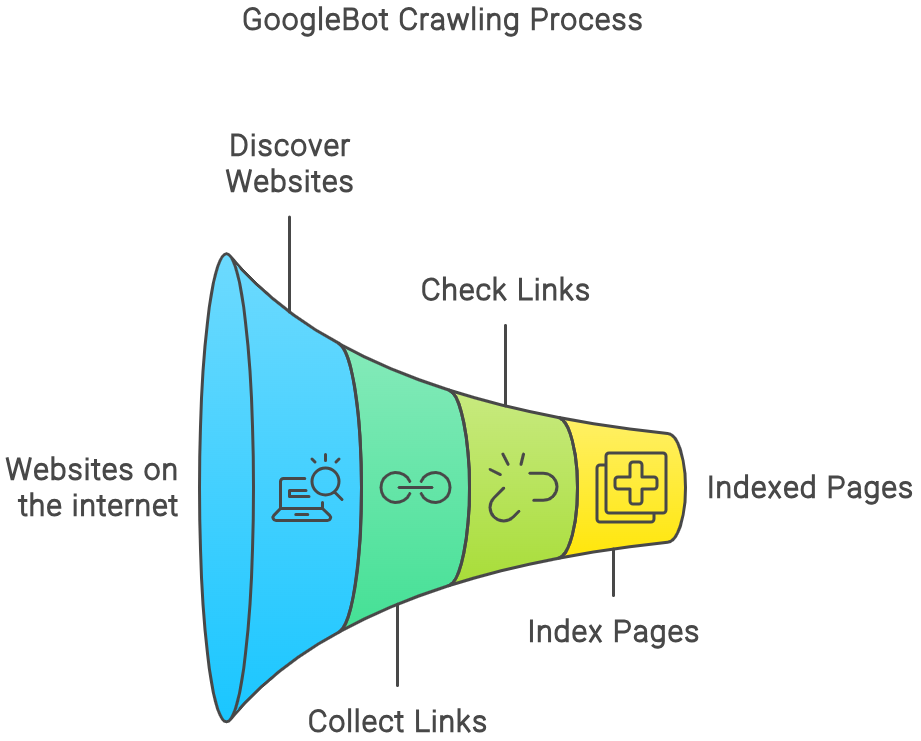
抓取(Crawling)
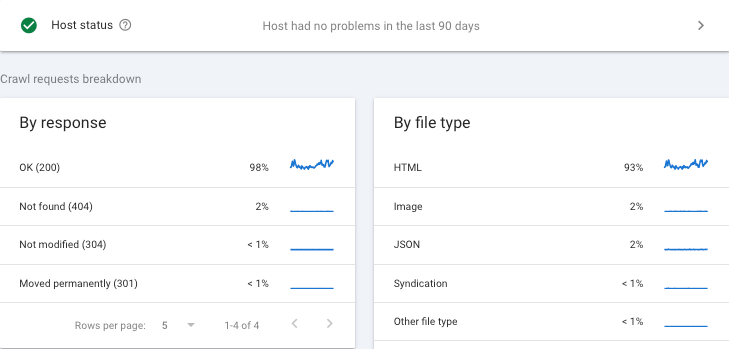
Google使用名为Googlebot的网页抓取工具(也称为蜘蛛程序)自动在互联网上发现网页。它通过访问已知网页上的链接,发现新的网页URL,也可以通过网站提交的站点地图(sitemap)获取网址。Googlebot会下载网页的文本、图片和视频等内容。抓取频率和抓取量由Google的算法决定,考虑网站响应速度和服务器负载,避免过度抓取导致网站压力过大。某些网页可能因robots.txt文件限制或需要登录而无法被抓取。 -
索引编制(Indexing)
抓取到网页内容后,Google会分析网页上的文本、图片、视频等信息,理解网页内容和结构,并将这些信息存储到Google的庞大索引数据库中。Google的索引系统名为Alexandria,它为每份内容分配唯一的DocID,处理重复内容时会将多个URL关联到同一DocID,实现内容的统一管理。索引过程还包括识别网页的规范版本,确保搜索结果的准确性和一致性。 -
搜索结果呈现(Serving)
当用户输入查询时,Google会在索引中搜索匹配的网页,并根据数百个因素(如相关性、用户位置、语言、设备等)排序,返回最相关的优质结果给用户。
补充说明:
- Googlebot的抓取策略会根据网站的响应情况动态调整抓取速度和频率,确保网站稳定运行。
- 网站结构清晰、URL简洁、站点地图完善,有助于Googlebot更高效地抓取和索引网页。
- 并非所有抓取的网页都会被收录,Google会根据网页质量和内容价值决定是否编入索引。
综上,Googlebot通过持续抓取网页,Google对内容进行分析和索引,最终为用户提供精准的搜索结果,这一机制确保了Google搜索的高效和准确。